
อัพเดทบริการ Amazon Athena ในปี 2024
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
บทความนี้แปลมาจากบทความที่เป็นภาษาญี่ปุ่นที่ชื่อว่า AWS入門ブログリレー2024〜 Amazon Athena 編〜 โดยเจ้าของบทความนี้คือ คุณ 石川覚
Amazon Athena คืออะไร
Amazon Athena เป็นบริการการคิวรีแบบ serverless ที่ AWS ให้บริการ แตกต่างจากโซลูชันดาต้าแวร์เฮาส์แบบดั้งเดิมตรงที่ Athena สามารถรันคิวรีในรูปแบบ SQL บน data lake ที่เป็นที่เก็บข้อมูลได้โดยตรง ช่วยให้สามารถเริ่มต้นการวิเคราะห์ข้อมูลได้ทันที โดยไม่ต้องจัดการกับเซิร์ฟเวอร์หรือการตั้งค่าโครงสร้างพื้นฐานใดๆ
ค่าบริการของ Athena จะขึ้นอยู่กับปริมาณข้อมูลที่คิวรีจริง ทำให้มีความคุ้มค่าด้านต้นทุนสูง และเป็นบริการที่เหมาะสมสำหรับองค์กรที่ต้องจัดการกับข้อมูลจำนวนมาก
Amazon Athena ไม่เพียงแต่เป็นเครื่องมือที่ใช้ในการวิเคราะห์ข้อมูลสำหรับ Data Engineer เท่านั้น แต่ยังเป็นเครื่องมือคิวรีที่มีประโยชน์สำหรับ Infrastructure Engineer ในการค้นหาและแสดงผลข้อมูลจาก log เช่น ALB (Application Load Balancer) และ CloudTrail อีกด้วย
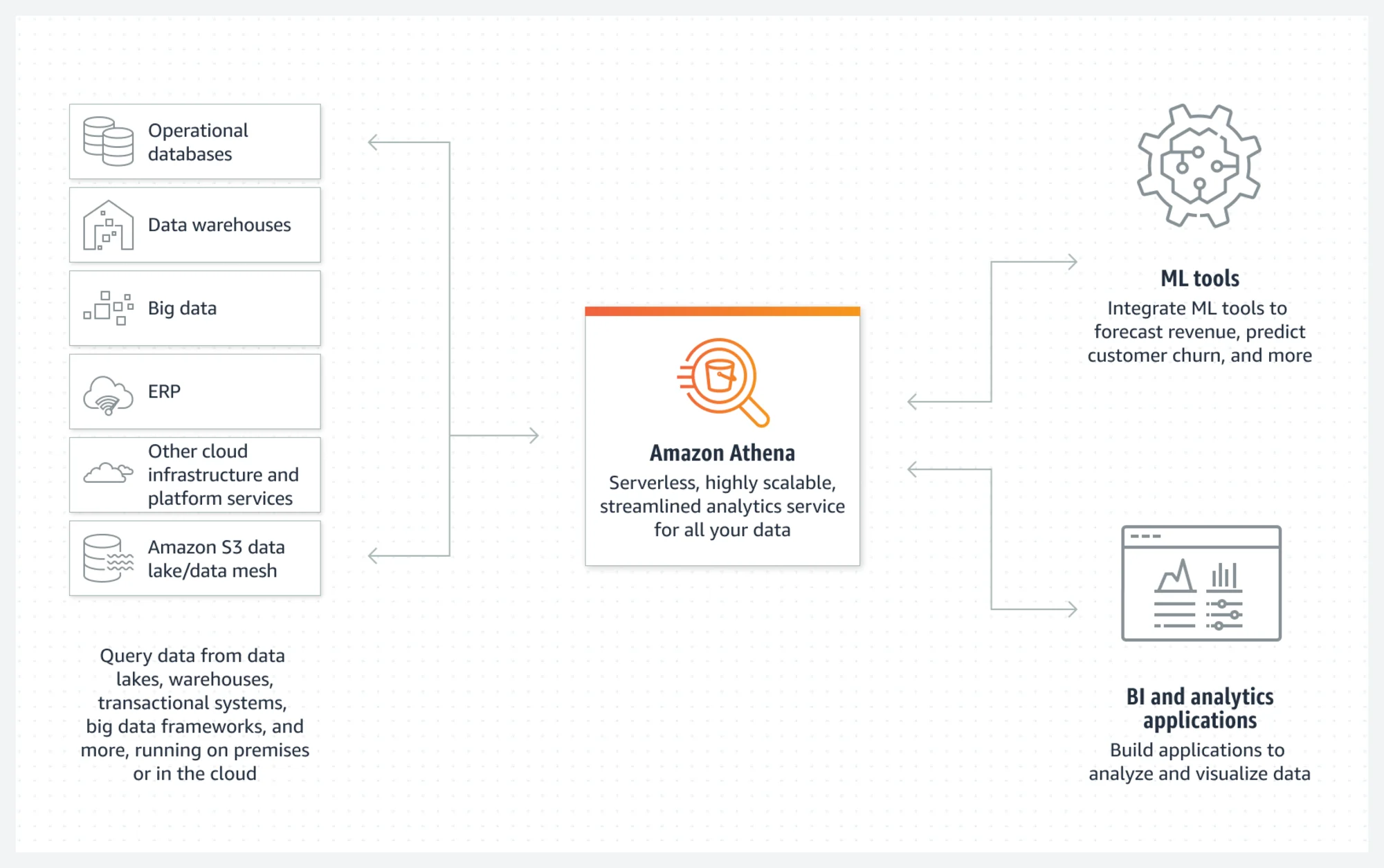
Athena และ Data Lake
Data Lake คืออะไร
Data Lake เป็นที่เก็บข้อมูลขนาดใหญ่ที่สามารถเก็บข้อมูลในรูปแบบและโครงสร้างต่างๆได้ ใน AWS Cloud ข้อมูลมักจะถูกเก็บใน S3 ซึ่งเรียกว่า S3 Data Lake องค์กรสามารถเก็บและใช้ข้อมูลทุกประเภท ไม่ว่าจะเป็นข้อมูลที่มีโครงสร้าง, ข้อมูลกึ่งมีโครงสร้าง, หรือข้อมูลที่ไม่มีโครงสร้าง การใช้ Data Lake ช่วยให้สามารถเก็บข้อมูลได้โดยไม่ต้องเลือกประเภทข้อมูล ทำให้การวิเคราะห์ในอนาคตมีความหลากหลายมากขึ้น นอกจากนี้ Data Lake ยังสามารถเก็บข้อมูลโดยไม่ต้องผ่านการประมวลผลล่วงหน้า ซึ่งช่วยลดต้นทุนในการเตรียมข้อมูลได้
Amazon Athena จะสามารถแสดงประสิทธิภาพสูงสุดเมื่อใช้งานร่วมกับ Data Lake
Data Format
การตัดสินใจว่าจะเก็บข้อมูลใน Data Lake ด้วยรูปแบบใดนั้นจะเรียกว่า Data Format รูปแบบของข้อมูลมีทั้ง HIVE และ ICEBERG การเข้าใจลักษณะและความแตกต่างของแต่ละรูปแบบจะช่วยให้การวิเคราะห์ข้อมูลมีประสิทธิภาพและประสิทธิผลมากขึ้น
HIVE
HIVE เป็นวิธีการที่ง่ายในการเก็บไฟล์ข้อมูลในโฟลเดอร์สำหรับข้อมูล และได้รับการใช้งานอย่างแพร่หลายเป็นรูปแบบตารางสำหรับการวิเคราะห์ข้อมูล สามารถดูข้อมูลได้ที่ Apache Hive
ใน HIVE ยังมีวิธีการแบ่งข้อมูลเชิงตรรกะที่เรียกว่า "Hive-Style Partitioning" หรือการ partition ซึ่งเป็นการแบ่งตารางออกเป็นส่วนย่อย ๆ หลายส่วน การ partition นี้ช่วยเพิ่มประสิทธิภาพและความสามารถในการขยายตัวของการวิเคราะห์ข้อมูล
การ partition แบบ Hive-Style ใช้โครงสร้างไดเรกทอรีในการแบ่งข้อมูล แต่ละไดเรกทอรีจะแทนค่าของ partition key และ value ตัวอย่างเช่น หากตารางมี partition key เป็น year และ month จะมีการสร้างโครงสร้างไดเรกทอรีดังนี้ เมื่อคุณระบุเงื่อนไขการกรองเป็นเดือนมกราคม 2023 ระบบจะสแกนเฉพาะโฟลเดอร์นั้น ทำให้ลดต้นทุนและเพิ่มประสิทธิภาพในการประมวลผล
/market_sales/
/year=2023/
/month=1/
/month=2/
/year=2024/
/month=1/
ไฟล์ข้อมูลจะถูกเก็บไว้ใต้โฟลเดอร์สุดท้าย รูปแบบข้อมูลที่รองรับมีหลายรูปแบบ เช่น CSV, JSON, Parquet, ORC, และ Regular Expression
อ้างอิง: Supported SerDes and data formats
ข้อจำกัดของ HIVE คือความสามารถในการจัดการข้อมูล (DML) ที่มีอยู่อย่างจำกัด โดยเฉพาะอย่างยิ่ง HIVE ไม่รองรับคำสั่ง DML เช่น DELETE, UPDATE, MERGE ทำให้ส่วนใหญ่จะถูกใช้งานสำหรับการอ้างอิงข้อมูล นอกจากนี้ HIVE ยังไม่สามารถเปลี่ยนแปลงประเภทข้อมูลของคอลัมน์หรือเพิ่ม/ลบคอลัมน์ได้ ดังนั้นในบางกรณี อาจจำเป็นต้องแปลงไฟล์บน S3 Data Lake ล่วงหน้าเพื่อรองรับการเปลี่ยนแปลงข้อมูล
ICEBERG (Apache Iceberg)
ICEBERG เป็นรูปแบบตารางที่พัฒนาขึ้นเพื่อแก้ไขข้อจำกัดของ HIVE และเพื่อให้สามารถวิเคราะห์ชุดข้อมูลขนาดใหญ่ได้อย่างมีประสิทธิภาพ ICEBERG มีฟีเจอร์ที่คล้ายกับดาต้าแวร์เฮาส์ทั่วไป เช่น ACID Transactions, การเปลี่ยนแปลง schema, และการปรับแต่ง partition ซึ่งช่วยเพิ่มความสมบูรณ์ของข้อมูลและประสิทธิภาพในการคิวรีข้อมูล การสนับสนุนใน Athena ทำให้สามารถคิวรีตาราง Iceberg ได้ง่ายขึ้นในสภาพแวดล้อมที่เป็น serverless สามารถดูข้อมูลได้ที่ Apache Iceberg
ICEBERG ไม่เพียงเก็บไฟล์ข้อมูลในรูปแบบ Parquet เท่านั้น แต่ยังเก็บไฟล์ meta data ด้วย ในไฟล์ meta data นี้จะประกอบด้วยข้อมูลต่าง ๆ เช่น schema ของตาราง, ข้อมูล partition, ประวัติการทำธุรกรรม ผู้ใช้งานไม่จำเป็นต้องกังวลเกี่ยวกับโครงสร้างของไฟล์เหล่านี้
การเปรียบเทียบระหว่าง HIVE และ ICEBERG
| หัวข้อ | HIVE | ICEBERG (Apache Iceberg) | เพิ่มเติม |
|---|---|---|---|
| Data Format | การเก็บไฟล์ข้อมูลในโฟลเดอร์สำหรับข้อมูล | รูปแบบตารางที่อิงตามเทคโนโลยี open source | |
| ACID Transactions | ไม่รองรับ | รองรับ | รับประกันความสมบูรณ์ของข้อมูล |
| การเปลี่ยนแปลง schema | จำเป็นต้องเปลี่ยนแปลงไฟล์ข้อมูลด้วย ไม่เพียงแค่การเปลี่ยนแปลง schema เท่านั้น | สามารถเปลี่ยนแปลงได้ด้วย DDL เท่านั้น | เพิ่มความยืดหยุ่นในการพัฒนา |
| ประสิทธิภาพ | เหมาะสำหรับการใช้งานที่เรียบง่าย | มี Overhead แต่โดยรวมแล้วมีประสิทธิภาพสูง | การเพิ่มประสิทธิภาพในการวิเคราะห์ข้อมูล |
| ฟังก์ชัน Data time travel | ไม่มี | มี | การเข้าถึงเวอร์ชันข้อมูลในอดีต |
| ค่าใช้จ่าย | ค่อนข้างต่ำ | เกิดค่าใช้จ่ายในการเก็บประวัติการอัปเดต | ความสมดุลกับงบประมาณ |
| การใช้งานที่เหมาะสม | การผสานรวมกับสภาพแวดล้อมที่มีอยู่และให้ความสำคัญกับค่าใช้จ่าย | ให้ความสำคัญกับACID Transactions, การเปลี่ยนแปลง schema, และประสิทธิภาพ | เลือกตามข้อกำหนดในการวิเคราะห์ข้อมูล |
ความแตกต่างระหว่าง Data Lake และ Data Warehouse ในการเป็นที่เก็บข้อมูล
เมื่อพูดถึงการวิเคราะห์ข้อมูลจำนวนมาก สิ่งแรกที่นึกถึงคือ Data Warehouse (DWH) ในที่นี้จะอธิบายความแตกต่างระหว่างทั้งสองแบบสั้น ๆ
Data Warehouse (DWH) มีความเชี่ยวชาญในการวิเคราะห์ข้อมูลที่มีโครงสร้าง ขณะที่ Data Lake สามารถเก็บข้อมูลทุกประเภทได้ไม่ว่าจะเป็นข้อมูลที่มีโครงสร้างหรือไม่มีโครงสร้าง
| Data Lake | Data Warehouse (DWH) | |
|---|---|---|
| Data Format | ข้อมูลที่มีโครงสร้างหรือไม่มีโครงสร้าง | ข้อมูลที่มีโครงสร้างเป็นหลัก |
| การประมวลผลข้อมูล | ไม่ต้องการการประมวลผล | จำเป็นต้องประมวลผลล่วงหน้า |
| Schema | Schema-on-Read | Schema-on-Write |
| Use Cases | การวิเคราะห์เชิงสำรวจ, machine learning | การวิเคราะห์แบบรูปแบบมาตรฐาน, การทำรายงาน |
| การขยายขนาด | ง่าย | ยาก |
| ค่าใช้จ่าย | ต้นทุนต่ำ | ต้นทุนสูง |
Data Lake และ Data Warehouse (DWH) มีความแตกต่างกันอย่างมากในด้านรูปแบบข้อมูล, การประมวลผลข้อมูล, การจัดการ schema, การใช้งาน, ความง่ายในการขยายขนาด, และค่าใช้จ่าย Data Lake สามารถเก็บข้อมูลในรูปแบบต่าง ๆ โดยไม่ต้องผ่านการประมวลผลล่วงหน้า ทำให้เหมาะสำหรับการวิเคราะห์เชิงสำรวจและ machine learning ขณะที่ Data Warehouse มักจะจัดการกับข้อมูลที่มีโครงสร้าง และเหมาะสำหรับการวิเคราะห์ที่เป็นรูปแบบและการทำรายงาน
การใช้รูปแบบ HIVE ใน Data Lake และการใช้รูปแบบ ICEBERG สำหรับการใช้งานที่ใกล้เคียงกับ Data Warehouse (DWH) เป็นอีกตัวเลือกหนึ่ง Amazon Athena มีข้อดีที่สำคัญคือสามารถผสมผสานข้อมูลจากรูปแบบตารางทั้งสองนี้ได้อย่างไร้รอยต่อ
Amazon Athena Query Engine
Amazon Athena สามารถใช้ engine ได้ 2 แบบ โดยสามารถตั้งค่า engine และเวอร์ชันสำหรับแต่ละกลุ่มงาน (workgroup) และเปลี่ยนแปลง engine หรือเวอร์ชันตามประสิทธิภาพและค่าใช้จ่ายของการคิวรีได้

Apache Trino (Athena SQL)
Apache Trino เป็นโปรเจกต์ที่แยกตัวออกมาในปี 2020 โดยพัฒนามาจาก Presto ซึ่งเป็น distributed SQL engine ที่พัฒนาโดย Facebook เดิมที Amazon Athena ใช้ query engine ที่พัฒนาขึ้นเองโดยอิงจาก Trino ทำให้สามารถใช้ฟีเจอร์ที่พัฒนามาจาก Presto ได้มากมาย สามารถดูข้อมูลได้ที่ Apache Trino
- โปรเจกต์ distributed SQL ที่เป็น open source ที่ใช้ใน engine เวอร์ชัน 3 ของ Athena
- ความสามารถแบบ on-demand (จะอธิบายภายหลัง) จะคิดค่าใช้จ่ายตามขนาดของแหล่งข้อมูลที่สแกน ทำให้เข้าใจต้นทุนได้ง่าย
หากต้องการรันคิวรีโดยใช้ Trino จาก Athena เพียงแค่เปิด Query editor และป้อน SQL จากนั้นคลิกที่ปุ่มรัน นอกจากนี้ AWS ยังมี JDBC ไดรเวอร์และ ODBC ไดรเวอร์ที่สามารถใช้ในแอปพลิเคชันที่มีการ embed ได้
ความแตกต่างระหว่างความสามารถแบบ on-demand และความสามารถแบบ provisioned capacity
ความสามารถแบบ on-demand เป็นสถาปัตยกรรมแบบ serverless ที่สามารถขยายขนาดได้อัตโนมัติ ไม่มีค่าใช้จ่ายเริ่มต้น และคิดค่าใช้จ่ายตามขนาดของข้อมูลที่สแกน
ในทางกลับกัน ความสามารถแบบ provisioned capacity เป็นสถาปัตยกรรมแบบคลัสเตอร์ที่สามารถจัดสรรทรัพยากรเฉพาะได้ ทำให้คาดหวังประสิทธิภาพสูง แต่ค่าใช้จ่ายในระยะยาวอาจสูงขึ้น
| หัวข้อ | On-demand | Provisioned capacity |
|---|---|---|
| แผนล่วงหน้า | ไม่จำเป็น | จำเป็น |
| การชำระเงิน | ขนาดของไฟล์ข้อมูลที่สแกน | ความจุที่จัดเตรียมไว้ |
| การเปลี่ยนแปลงของ workload | รองรับได้ง่าย | รองรับได้ยาก |
| การคิวรีแบบฉับพลัน | รองรับได้ง่าย | ต้องการความสามารถเพิ่มเติม |
| ค่าใช้จ่าย | มีเปลี่ยนแปลง | คงที่ |
| เวลาการรันคิวรี | อาจใช้เวลานาน | สามารถย่นระยะเวลาได้ |
| ประสิทธิภาพ | มีเปลี่ยนแปลง | เสถียร |
หากเวิร์กโหลดมีการเปลี่ยนแปลงหรือมีการคิวรีแบบฉับพลันเกิดขึ้น ความสามารถแบบ On-demand (ค่าเริ่มต้น) จะเหมาะสมกว่า แต่หาก workload สามารถคาดการณ์ได้และมีความเสถียร ควรเลือกใช้ความสามารถแบบ Provisioned capacity ในกรณีที่ต้องการความสมดุลระหว่างต้นทุนและประสิทธิภาพ สามารถใช้ทั้ง 2 แบบร่วมกันได้
Partition Projection
Partition Projection จะคำนวณ partition จากกฎและรูปแบบของ partition key ที่กำหนดในนิยามตาราง และทำการตัด partition (Partition Pruning) โดยอัตโนมัติ ทำให้ไม่จำเป็นต้องตั้งค่า partition สำหรับแต่ละ partition ที่ต้องการ ซึ่งเป็นฟีเจอร์ของ Athena ที่ช่วยลดภาระในการดำเนินงาน
Apache Spark (Athena for Spark)
Apache Spark เป็นเฟรมเวิร์กการประมวลผลแบบคลัสเตอร์ open source ที่ออกแบบมาเพื่อการประมวลผลข้อมูลขนาดใหญ่ ด้วยคุณสมบัติเหล่านี้ Amazon Athena จึงสามารถใช้ประโยชน์จากการประมวลผลแบบ parallel distributed, การคำนวณในหน่วยความจำ, ความทนทานต่อความผิดพลาด, การรองรับแหล่งข้อมูลต่าง ๆ, และการปรับแต่งคิวรีของ Apache Spark เพื่อให้สามารถรันคิวรีข้อมูลขนาดใหญ่ได้อย่างรวดเร็วและมีความน่าเชื่อถือสูง สามารถดูข้อมูลได้ที่ Apache Spark™ - Unified Engine for large-scale data analytics
- เฟรมเวิร์กการประมวลผลแบบกระจาย open source ที่ใช้ใน Amazon Athena Engine เวอร์ชัน 1
- การคิดค่าใช้จ่ายตามเวลาที่ใช้โน้ตบุ๊กและจำนวน DPU (Data Processing Units) ที่ใช้ในการรันคิวรี
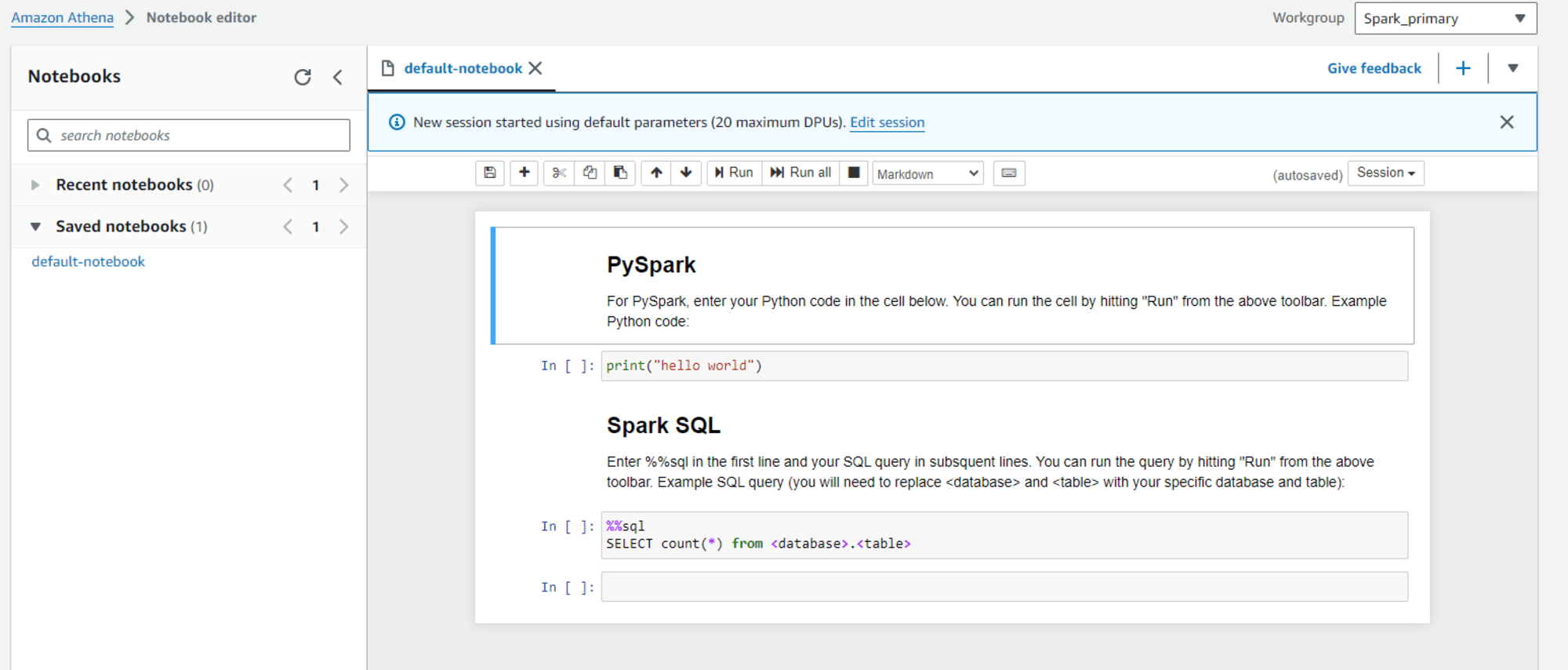
- Spark ไม่เพียงรองรับ SQL (SparkSQL) เท่านั้น แต่ยังสามารถวิเคราะห์ข้อมูลด้วยภาษาโปรแกรมต่าง ๆ เช่น PySpark และ Scala ทำให้มีความยืดหยุ่นสูง
หากต้องการใช้ Spark จาก Athena จะต้องรันคิวรีจากโน้ตบุ๊ก (Jupyter Notebook) แทนที่จะใช้ Query editor
การคิวรีแบบ Federated Query ที่สามารถคิวรีข้อมูลจากแหล่งข้อมูลหลากหลายประเภทได้
เพื่อหลีกเลี่ยงความสับสน เราได้อธิบายว่า "Athena เป็นบริการสำหรับคิวรีข้อมูลใน S3 Data Lake" อย่างไรก็ตาม จริง ๆ แล้วมีฟีเจอร์ที่เรียกว่า Federated Query ซึ่งสามารถรันคิวรีกับแหล่งข้อมูลภายนอกได้ด้วย การพัฒนาและ deploy จาก data source connector ของ Apache Trino จะทำให้สามารถคิวรีข้อมูลจากแหล่งข้อมูลหลากหลายประเภทได้
อ้างอิง: Using Amazon Athena Federated Query
Available data source connectors
Amazon Athena Google BigQuery connector
Use Cases
แนะนำการใช้งานที่ใช้ประโยชน์จากความสามารถในการคิวรีข้อมูลที่ยืดหยุ่นของ Amazon Athena
| Use Cases | อธิบาย | ตัวอย่าง |
|---|---|---|
| การวิเคราะห์แบบ Ad Hoc | Data analyst และ Business analyst ใช้การวิเคราะห์แบบ Ad Hoc เพื่อค้นหาข้อมูลเชิงลึกใหม่ ๆ จากข้อมูลที่มีอยู่ โดยใช้ทักษะ SQL ในการสำรวจข้อมูลและค้นพบสิ่งใหม่ ๆ | การวิเคราะห์ข้อมูลการขาย |
| การเก็บรวบรวมและวิเคราะห์ข้อมูล IoT | สามารถเก็บข้อมูลจำนวนมาก เช่น ข้อมูลเซนเซอร์ที่รวบรวมจากอุปกรณ์ IoT ไว้ใน S3 Data Lake และใช้ Athena เพื่อวิเคราะห์ข้อมูลแบบเรียลไทม์ได้ | การใช้ประโยชน์จากข้อมูล IoT จะง่ายขึ้น |
| Data Pipeline | ดึงข้อมูลจาก S3, แปลงข้อมูล, และโหลดไปยังที่เก็บข้อมูลอื่น | วิเคราะห์ข้อมูลลูกค้าและสร้างแคมเปญการตลาด |
| Machine Learning | ทำการประมวลผลข้อมูลเบื้องต้นที่จำเป็นสำหรับการฝึกโมเดล Machine Learning โดยดึงและแปลงข้อมูลเฉพาะจาก Big data เพื่อให้ได้รูปแบบที่สามารถใช้กับอัลกอริธึมของ Machine Learning ได้ | การประมวลผลข้อมูลเบื้องต้นของ Machine Learning |
| Security และ Audit | วิเคราะห์ข้อมูล Security log และ Audit log เพื่อระบุภัยคุกคามหรือความผิดปกติที่อาจเกิดขึ้น | วิเคราะห์ข้อมูลเครือข่ายเพื่อการตรวจจับการโจมตีทางไซเบอร์ |
| การวิเคราะห์ log | วิเคราะห์ log หลากหลายประเภท เช่น server log, application log, และ clickstream data เพื่อระบุรูปแบบการเข้าถึง, ตรวจจับการละเมิดความปลอดภัย และเฝ้าติดตามประสิทธิภาพของระบบ | วิเคราะห์การใช้งานคลาวด์และปรับแต่งทรัพยากรให้เหมาะสม |
| Business Intelligence | วิเคราะห์ข้อมูลการขาย, ข้อมูลลูกค้า, และข้อมูลการตลาด เพื่อให้ได้ข้อมูลเชิงลึกเกี่ยวกับประสิทธิภาพทางธุรกิจ | วิเคราะห์ความพึงพอใจของลูกค้าและนำไปใช้ในการปรับปรุงผลิตภัณฑ์ |
ค่าใช้จ่าย
สามารถดูได้ที่นี่โดยอ้างอิงกับภูมิภาคสิงคโปร์
กรณีใช้ Query Engine : Apache Trino
ค่าใช้จ่ายสำหรับความสามารถแบบ on-demand (SQL Query)
- 5 USD ต่อ 1TB ของข้อมูลที่สแกน
- จำนวนไบต์จะถูกปัดขึ้นเป็นเมกะไบต์ และจะมีการคิดค่าใช้จ่ายขั้นต่ำ 10 MB ต่อคิวรี
ค่าใช้จ่ายสำหรับความสามารถแบบ Provisioned Capacity
- 0.37 USD ต่อชั่วโมง x จำนวน DPU (ขั้นต่ำ 24)
- ค่าใช้จ่ายสำหรับช่วงเวลาที่ใช้งานในบัญชี (ขั้นต่ำ 1 ชั่วโมง)
- ในแต่ละบัญชีและแต่ละภูมิภาค สามารถสร้างการจองความสามารถได้สูงสุด 100 รายการ โดยมี DPU รวมสูงสุด 1,000 DPU
กรณีใช้ Query Engine : Apache Spark
Apache Spark ประกอบด้วยโหนดไดรเวอร์หนึ่งตัวและโหนดเวิร์กเกอร์หลายตัว ไดรเวอร์จะจัดการงานตามตารางที่ตั้งไว้ และส่งงานไปยังเวิร์กเกอร์ จากนั้นเวิร์กเกอร์จะประมวลผลและส่งผลลัพธ์กลับไปยังไดรเวอร์
ดังนั้น ในกรณีของ Apache Spark ค่าใช้จ่ายจะเป็นผลรวมของเวลาการใช้งาน DPU ของไดรเวอร์และเวลาการใช้งาน DPU ของเวิร์กเกอร์
- เวลาการใช้งาน DPU ของไดรเวอร์คือเวลาตั้งแต่เริ่มเซสชันจนถึงสิ้นสุดเซสชัน
- เวลาการใช้งาน DPU ของเวิร์กเกอร์คือผลรวมของเวลาที่เวิร์กเกอร์ใช้ตั้งแต่เริ่มทำงานจนถึงหยุดทำงาน
- 0.45 USD x (เวลาการใช้งาน DPU ของไดรเวอร์ + เวลาการใช้งาน DPU ของเวิร์กเกอร์)
สรุป
Amazon Athena เป็นบริการคิวรีแบบ serverless และสามารถขยายขนาดได้ ด้วย Athena คุณสามารถรันคิวรี SQL บนข้อมูลใน Data Lake ที่เก็บในรูปแบบต่าง ๆ ได้ ทำให้การเริ่มต้นวิเคราะห์ big data เป็นเรื่องง่าย Athena สามารถนำไปใช้ในกรณีการใช้งานหลากหลาย เช่น การวิเคราะห์ log, การวิเคราะห์ข้อมูล IoT, Machine Learning, และการสำรวจข้อมูล เนื่องจากเป็นบริการที่คิดค่าใช้จ่ายตามการใช้งานจริง จึงไม่มีค่าใช้จ่ายเริ่มต้นและช่วยลดต้นทุนในการวิเคราะห์ข้อมูลขนาดใหญ่
บทความต้นฉบับ
- AWS入門ブログリレー2024〜 Amazon Athena 編〜(ภาษาญี่ปุ่น)










